RTX Spark vs Mac M5 Max vs RTX 5090|ローカルLLM実測比較・帯域と価格
「生成AIを、自分のPCの中で動かしたい」。
そう思って機材を調べ始めた人の前には、これまでずっと2つの選択肢が並んでいました。
Mac(M5 Max)か、RTX 5090を積んだデスクトップか。
そこへ2026年6月、NVIDIAのRTX Sparkが割り込んできました。
128GBの統合メモリとCUDAを薄型ノートに積んだという、これまで存在しなかった1台です。
「RTX Spark」で検索してここにたどり着いたあなたが知りたいのは、たぶんこの一点ですよね。
結局これは、自分の“本命候補”に入ってくるのか?
私も、LLMの講座を3年前に受講してから、「ローカルで生成AIを動かしたい」という目標があります。
LLMを学べば、最終地点はそこにあることがわかります。
しかし、私には多額な予算もなく、実現に至りません。
先に、この記事が誰のためのものかをはっきりさせておきます。
クラウドなら安く生成AIが使える今、あえて数十万円のローカル機を組む理由は、だいたい2つに絞られます。
機密情報や社外秘を、外のサーバーに出さずに扱いたい。
たとえば自治体案件のように情報漏えいが許されない仕事だと、クラウドの生成AIはそもそも使えない。
これから上がっていくAPI料金に先回りして、ローカル環境へ先行投資しておきたい。
この記事は、その目的を持つ人に向けて、RTX Spark・Mac M5 Max・RTX 5090の3台を、スペックだけでなく実測のトークン速度まで並べて突き合わせます。
逆に、「そもそもRTX Sparkって何? ふだん使いのPCを、今買うべきか秋まで待つべきか」というシンプルな疑問についての記事はこちら↓の記事で書いています。
≫ RTX Sparkを待つべきか・買うべきかの判断ガイド
この記事は、その一歩先。ローカルAIを本気で動かす前提で進めます。
情報はNVIDIA公式(製品ページ)・Arm・MediaTek・Microsoft・Appleの各公式発表がベース(2026年6月時点)。
価格や発売日など、まだ正式発表されていない項目は「予想」とはっきり区別して書きます。
- 結論から:一般用途なら今買う、ローカルAI本気なら本命はMac M5 Max か RTX 5090
- ローカルAI目線で見たRTX Sparkの“素性” — 効くスペックは4つだけ
- 128GBの統合メモリが効く理由(そして、Macとどう違うのか)
- 正直な懸念 — Windows on Arm とエミュレーション問題
- Apple M5 Max(614GB/s)vs RTX Spark(300GB/s)— 帯域だけ見ると意外な結果
- 生成AIをやるなら、MacとWindowsどっち?
- 生成AIの「2台目」をどれにする? — 本命はMac M5 Max と RTX 5090(RTX Sparkは?)
- Claude Code を VS Code で動かすなら? — Windows on Arm・Windows・Mac の違い(2026年6月時点)
- ローカルLLMを入れてClaude Codeで動かすなら? — RTX 5090・Mac M5・RTX Spark で何が変わる
- 結局、3台のどれを選ぶか — タイプ別の判断
- よくある質問(FAQ)
- まとめ
結論から:一般用途なら今買う、ローカルAI本気なら本命はMac M5 Max か RTX 5090

用途がゲームや一般作業で、今すぐPCが要るなら、現行モデルを買って問題ありません。
生成AIをローカルで本気で動かしたいなら、本命はMac M5 MaxかRTX 5090。
情報収集した結果、2026年6月現在での話になりますが、
話題のRTX Sparkは“速度の壁”で本命からは外れがち、というのがこの記事の結論です。
意外に思うかもしれません。
128GB×CUDA×持ち運びというRTX Sparkの組み合わせは新しいのに、なぜ本命にならないのか。
理由は、開発で効くメモリ帯域が3者で一番低いからです。
この記事は、価格やスペックだけでなく、実測のトークン速度まで並べて、その理由を一つずつ分解していきます。
とにかく「買うか待つか」だけ先に知りたい人は、RTX Sparkを待つべきか・買うべきかの判断ガイドに要点だけまとめています。
ローカルAI目線で見たRTX Sparkの“素性” — 効くスペックは4つだけ
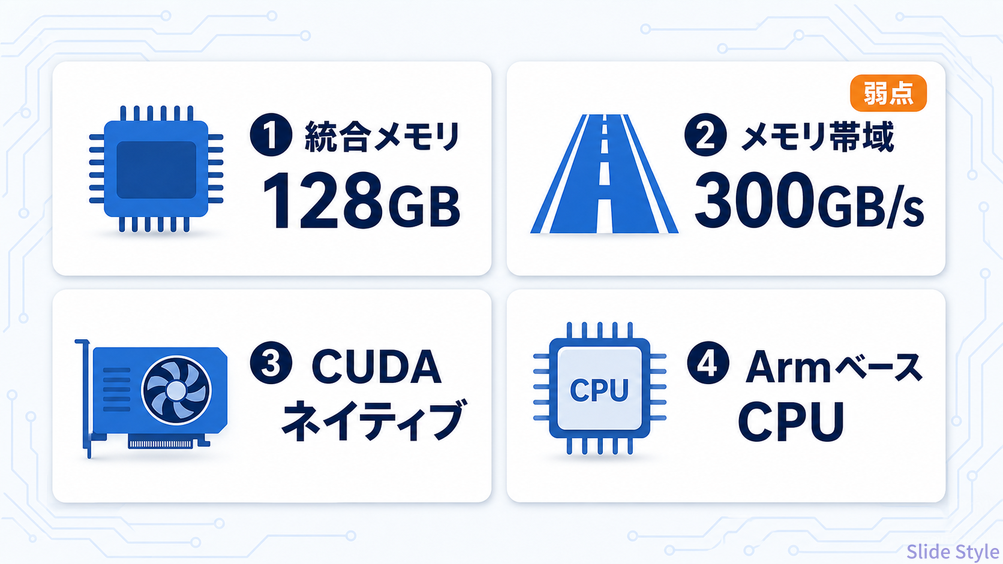
RTX Sparkが何者かという成り立ちや、価格の予想・発売時期・搭載予定の6機種といった“買う前のベース”は、RTX Sparkを待つべきか・買うべきかの判断ガイドで解説しています。
この記事ではローカルAIの“使えるかどうか”を分けるスペックだけに絞ります。
| 項目 | 仕様 |
| GPUアーキテクチャ | Blackwell RTX GPU |
| CUDAコア数 | 最大6,144コア |
| CPU | NVIDIA Grace CPU(Armベース・20コア・MediaTek共同設計) |
| AI演算性能 | 最大1ペタフロップス(FP4) |
| 統合メモリ | 最大128GB(LPDDR5X) |
| メモリ帯域 | 最大300GB/s |
| 製造プロセス | TSMC 3nm |
| ソフトウェア基盤 | NVIDIA CUDA ネイティブ |
スペック表は長いですが、ローカルでLLMを動かす人が見るべきは、たった4行です。
- 統合メモリ128GB:どれだけ大きいモデルを“載せられるか”。120B級の巨大LLMも丸ごと収まる容量です
- メモリ帯域300GB/s:載せたモデルをどれだけ“速く”回せるか。帯域が後半の主役になります
- CUDAネイティブ:最新のAIツールやフレームワークが、翻訳なしでそのまま動くかどうか
- ArmベースのCPU:ふだんのWindowsアプリの互換性に影響する土台。詳しくは後の章で
注目してほしいのは、容量(128GB)は規格外に大きいのに、帯域(300GB/s)はこのクラスにしては控えめ、という“ねじれ”です。
この1点が、RTX Sparkの評価をまるごと左右します。
なぜそう言い切れるのかを、ここからMac M5 Max・RTX 5090と実測で突き合わせていきます。
128GBの統合メモリが効く理由(そして、Macとどう違うのか)
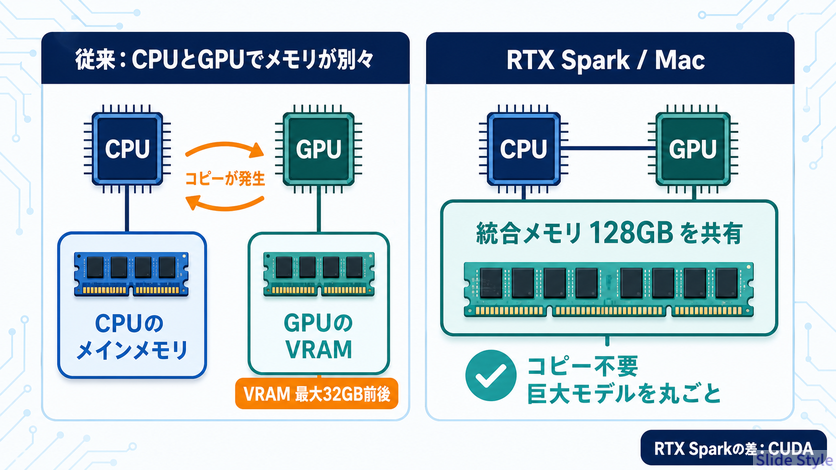
128GBの統合メモリは、AIをやる人にとって本丸です。
なぜ128GBの「統合」メモリがそれほど効くのか。
一般的なWindowsノートでは、CPUのメインメモリとGPUのVRAMが別物でした。
GPUにデータを渡すたびにコピーが発生し、しかもコンシューマ向けGPUのVRAMは最大でも32GB前後で頭打ち。
だから大きなAIモデルは、メモリに載りきらず動かないか、極端に遅くなっていました。
「大容量の統合メモリ」そのものは、RTX Sparkの発明ではありません。
先に実現していたのはAppleで、Mac(M5 Max)も最大128GBの統合メモリを積めます。
「巨大モデルをまるごと載せられる」という一点だけなら、Macでも前からできていたわけです。
RTX Sparkの新しさは、その大容量の統合メモリをNVIDIAのCUDAで、しかも持ち運べるWindowsノートで使える点にあります。
CPUとGPUが同じ128GBのプールを共有し、コピーの手間なく巨大なモデルを置ける。
そこまではMacと同じで、違うのは、AI開発で事実上の標準になっているCUDAがそのまま手元で動くことです。
- 大規模モデルがローカルで動く:1,200億パラメータ(120B)級のLLMを最大100万トークンのコンテキストで手元実行(NVIDIA公式値)
- クラウド不要:APIの従量課金、通信レイテンシ、機密データの外部送信リスクを回避
- CUDAが手元にある:MacのMLX系と違い、CUDA前提の最新フレームワークやサンプルがそのまま動きやすい
- 帯域は最大300GB/s(弱点):容量は大きい一方で、データを送り込む速さはMac M5 Maxの約614GB/sより低い。巨大モデルを“速く”回す場面では、帯域がボトルネックになりがちです
華々しいデビューとはいえ、何もかもを期待するのは少し気が早いのかもしれません。
「データセンターと同じCUDA」とはいえ、RTX SparkはArmベースのWindowsモデル。
Arm版でどこまで開発ツールやライブラリが揃うかは、まだ実機で確かめないと分からない部分が残ります(この点はあとの「Windows on Arm」の章で掘り下げます)。
私自身、生成AIのコード補助を日常的に使う身として、CUDAを持ち歩けるという発想自体は刺さりました。
ただ、その魅力が実際の速度やArm対応に見合うかは、価格と発売後の検証しだいだと見ています。
正直な懸念 — Windows on Arm とエミュレーション問題
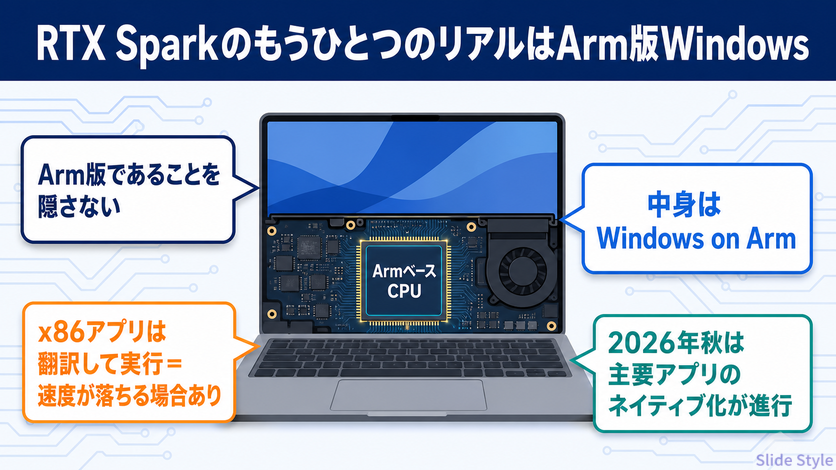
Arm版であることを書かない記事は、信用できません。
RTX SparkのCPUは Arm アーキテクチャ です。
Armチップ上でWindowsを動かす「Windows on Arm」という構成には、2年前から続く根深い問題があります。
まず確定事実:RTX Spark が Arm 版であることは公式4社が認めている
Arm版かどうかは曖昧にできない部分なので、公式ソースで固めます。
| 根拠(公式発言) | 発言主 | 出典 |
| 「Powered by the Arm-based NVIDIA Grace CPU」/記事タイトル「Arm-based NVIDIA RTX Spark」 | Arm社 公式newsroom | newsroom.arm.com |
| 「a high-performance, 20-core NVIDIA Grace™ CPU」/「MediaTek … collaborated with NVIDIA on the custom CPU design」 | NVIDIA公式プレスリリース | nvidianews.nvidia.com |
| NVIDIAと協業し、RTX Spark のカスタム Arm CPU を設計 | MediaTek公式 | mediatek.com |
| 「Windows on Arm」「PrismをRTX Spark向けに最適化」 | Microsoft公式(Windows Blog) | blogs.windows.com |
CPUの正式名称は、NVIDIA・Arm両社の公式発表が明記する「NVIDIA Grace CPU」(Armベース・20コア)。
設計はNVIDIAとMediaTekの共同で、NVLink-C2CでBlackwell GPUと接続する構成です。
チップを作ったArm社自身が記事タイトルに「Arm-based」と掲げているので、Arm版であることはもう議論の余地がありません。
補足すると、コア構成(Cortex-X925×10+Cortex-A725×10、最大4.1GHz)やチップのコードネーム「N1x」は、現時点ではNVIDIA公式文書に記載がない非公式情報です。
ところが面白いことに、NVIDIAの日本語製品ページには「Arm」の表記が一切ありません。
NVIDIA Newsroomや公式Xが前面に出すのは「Windowsネイティブのエージェント」と「NVIDIAのAI&グラフィックス技術」。
同じ1個のチップを、Arm社は「Armチップ」として、NVIDIAは「AIエージェントPC」として語っているわけです。
正直、私はこの売り方に戦略を感じます。
「Arm/Windows on Arm」という言葉には、後述するSnapdragonの負の印象がこびりついている。
だからNVIDIAはその言葉を避け、30年分の技術(CUDA・RTX・DLSS・FP4・TensorRT・OptiX・Reflex・G-SYNC)と、Windows上で自律的に動くエージェントという“前向きな顔”で勝負しています。
裏側はArmでも、表向きは「AIが働くPC」。
このイメージ戦略がハマるかどうかも、普及の鍵になりそうです。
「半分の性能」の正体は、チップではなくプラットフォーム
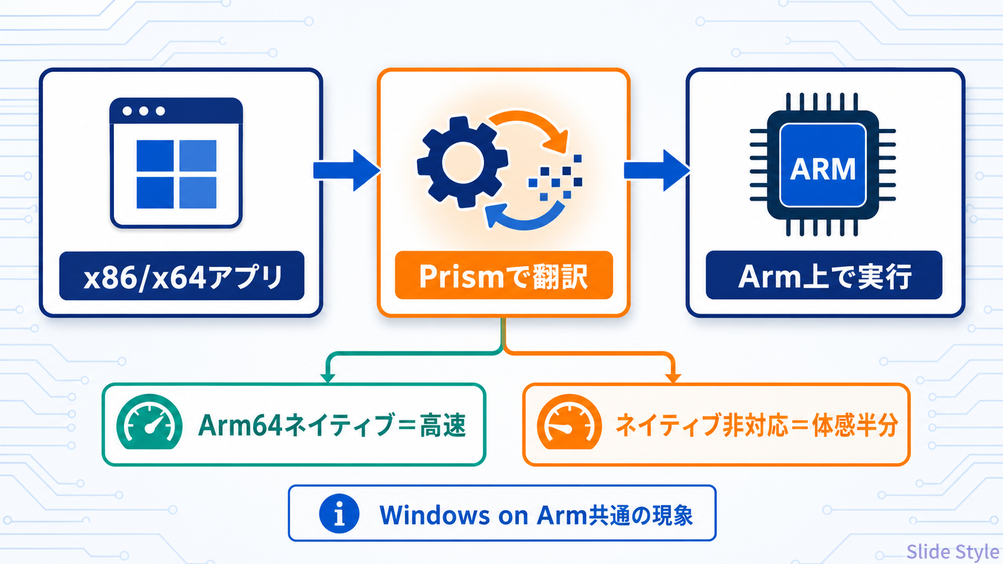
Snapdragonを作っているのはNVIDIAではなく、Qualcomm(クアルコム) です。
RTX SparkとSnapdragonは、別会社の競合チップ。
| チップ | 製造元 | CPU設計 |
| Snapdragon X / X Elite | Qualcomm | Qualcomm自社(Oryon) |
| RTX Spark | NVIDIA | NVIDIA Grace CPU(Armベース・20コア・MediaTek共同設計) |
レビュー機で確認していますが、2024年から出ているSnapdragon搭載PCでは、Premiere Proなどが本来の速度を出せず、体感で半分近くまで落ちる場面がありました。
あれはSnapdragonというシリコンの欠陥ではありません。
x86/x64用に作られたアプリを、Microsoftの Prism というエミュレーション層が翻訳して動かすために起きる、Windows on Arm共通の現象です。
原因は「そのアプリにArm64ネイティブ版があるか」であって、チップメーカーが誰かは関係ありません。
だからRTX Sparkも、この互換性事情をそっくり相続します。
NVIDIAだから魔法のように解決、とはなりません。
ただし2026年秋は、2年前よりかなりマシ
互換性は、2年前よりかなり良くなっている——少なくとも、各社の発表ではそう説明されています。
ただ、私自身はこれを鵜呑みにはできません。
先ほどのPremiere Proの遅さに加えて、そもそもSnapdragon PCの初期設定に一度も成功したことすらない。
Arm版にはこうした“ハマりどころ”があるので、「改善した」と言い切るのは控えておきます。
- Adobe Premiere Pro / After Effects / Audition / Media EncoderはArm64ネイティブ化済み(v26.0〜)
- ただし初期版はサードパーティプラグイン、一部RAW/ProRes、一部H.264/HEVCのハードウェアデコードが未対応
- Prism自体も高速化し、レガシー64bitアプリも実用域。ただしバッテリー消費は15〜20%増
- 現代ワークフローの主要アプリは、2026年にはほぼネイティブ対応
そして、アプリ互換への本気度が、今回いちばんの朗報です。
NVIDIAとMicrosoftは、Snapdragon時代に一番嫌われた「アプリが動かない」問題を、正面から潰しに来ています。
- PrismエミュレータをRTX Spark専用にチューニング(Microsoft公式)。x86アプリの翻訳実行を高速化
- ジェンスン・フアンCEOが「過去のあらゆるWindowsアプリを動かす」と明言
- アンチチート(Easy Anti-Cheat/BattlEye)がネイティブ対応 → Fortnite・VALORANT・PUBGがArm上で起動。Snapdragonで一番不評だった「ゲームが動かない」への直接回答
- Xbox PCアプリ対応、Windows 11のタスクスケジューラ自体をRTX Spark向けに刷新
Snapdragonが2年かけても埋めきれなかった穴を、NVIDIA・Microsoft・ゲーム会社が総がかりで塞ぎに来た構図。
私がRTX Sparkに本気度を感じたのは、まさにこの一点です。
NVIDIA側の固有の強みもあります。
GPU・CUDA・レイトレ・DLSSはネイティブ動作で、GPU処理はエミュレーションを通りません。
Snapdragon X Elite Gen2比でレイトレ性能4倍、マルチスレッド処理(Blender)は統合メモリの効果で41%上回るというデータも出ています。
一方でCPUのシングルスレッドはQualcomm比で約8%劣る、というのが現時点の評価。
本当の敵は「Windows on Arm=Snapdragon=遅い」の刷り込み
実は、Snapdragonが残した刷り込みが一番のハードルだと私は見ています。
2年間、Windows on Armの顔はSnapdragonでした。
その結果、「Arm版Windows=アプリが動かない・遅い」という負の印象が世間に定着しています。
RTX Sparkはこの先入観を背負わされた状態でスタートします。
Qualcomm株は発表当日に7%下落し、Qualcomm自身が「ようこそ」と皮肉混じりにコメントしたほど。
NVIDIAがこの誤解を解けるかどうかが、普及の分かれ目。
Apple M5 Max(614GB/s)vs RTX Spark(300GB/s)— 帯域だけ見ると意外な結果

「結局Macと比べてどうなの」という疑問に、数字で答えます。
2026年3月発売のMacBook Pro(M5 Max)と比較しました。
その前に、よく聞かれる「M5っていくつ種類があるの」を片付けておきます。
2026年6月時点のM5ファミリーは、下の4つ。
| チップ | 統合メモリ上限 | メモリ帯域 | 主な搭載機・発表 |
| M5(無印) | 32GB | 153.6GB/s | MacBook Pro 14 / iPad Pro(2025年10月) |
| M5 Pro | 64GB | 307GB/s | MacBook Pro(2026年3月) |
| M5 Max | 128GB | 460GB/s(32コアGPU)/614GB/s(40コアGPU) | MacBook Pro(2026年3月) |
| M5 Ultra | さらに上(⚠️予想) | 614GB/s超の見込み(⚠️予想) | Mac Studio(2026年秋予定・公式未発表) |
上3つはApple公式の確定値、いちばん下のM5 Ultraだけ公式未発表の予想です。
ローカルAIで大型モデルを丸ごと載せたいなら、128GBに届くのは M5 Max以上 だけ。
M5 Proは上限64GB・帯域307GB/sで、RTX Sparkの約300GB/sとほぼ同じ帯域なので、大型モデルの速度差はほとんど出ません。
だからRTX Sparkの正しい比較相手は、容量も帯域も上を狙えるM5 Max。
以下はそのM5 Maxとの一騎打ちです。
| 項目 | RTX Spark | Apple M5 Max |
| 統合メモリ | 最大128GB | 最大128GB |
| メモリ帯域 | 最大300GB/s | 最大614GB/s(40コアGPU構成) |
| アーキテクチャ | Blackwell GPU + Arm CPU | Apple Silicon |
| エコシステム | CUDA(業界標準) | Metal / MLX |
| OS | Windows on Arm | macOS |
先に「メモリ帯域」をかみ砕きます。
これは、メモリからチップへデータを送り込む“道路の車線数”のようなもの。
車線が広いほど一度に多く運べて、AIが答えを書き出す速度も上がります。
容量(128GB)が「どれだけ大きい荷物を置けるか」なら、帯域(GB/s)は「その荷物をどれだけ速く運べるか」です。
その目で見ると、実はM5 Maxの614GB/sがRTX Sparkの300GB/sを大きく上回ります。
両方とも128GBの統合メモリなのに、帯域では意外な逆転。
車線の広さが倍違うので、メモリ帯域が効くAI推論では、M5 Maxが有利な場面も出てきます。
ではRTX Sparkの価値はどこにあるのか。
答えは CUDA です。
CUDAは、NVIDIA製GPUでAIを動かすための土台(部品をつなぐ共通言語)で、いまの業界標準。最新のAIツールの多くがこれを前提に作られています。
従来、CUDAをフルに使える128GBクラスの環境は、デスクトップのデータセンター機しかありませんでした。
それを薄型Windowsノートに持ち込んだのがRTX Sparkの本質。
帯域では負けても、ソフトウェア資産の豊富さで戦う構図です。
生成AIをやるなら、MacとWindowsどっち?
MacとWindowsの選択は、多くの人が迷うポイント。
2026年時点のローカルAIの実情を、数字で整理します。
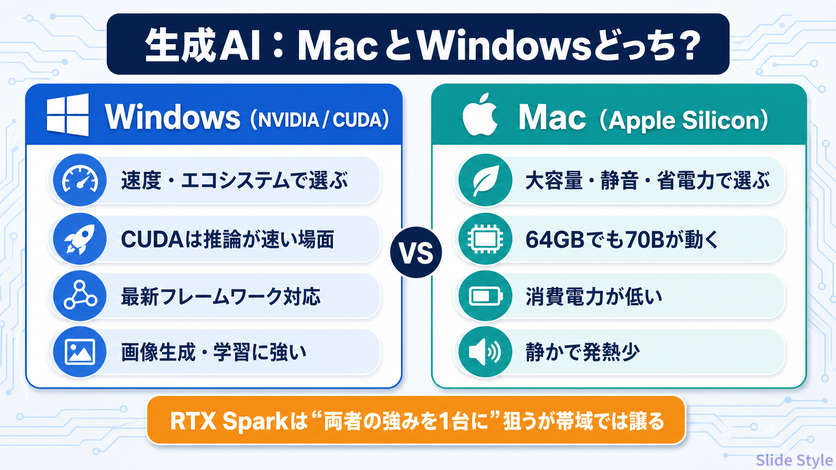
速度・エコシステムで選ぶならNVIDIA(CUDA)。
CUDAはMLXより推論が2〜4倍速い場面があり、新しいモデルやフレームワーク(vLLM、Unsloth等)はCUDA前提で設計されることが多い。
画像生成や学習タスクもNVIDIAが強い領域です。
大きなモデルを載せる・静音・省電力で選ぶならMac。
Apple Siliconの統合メモリは、64GB機でも70Bモデルを15〜20トークン/秒で動かせます。
MLXは新モデルへの対応が速く、消費電力も圧倒的に低い。
発熱と騒音が少ないのも日常使いでは効きます。
そしてRTX Sparkの立ち位置は、この両者の強みを1台に束ねようとしたもの。
Macのような大容量統合メモリと、NVIDIAのCUDAエコシステムを1台に。
ただし帯域ではM5 Maxに譲るので、メモリ帯域がボトルネックになる用途では、まだMacが勝つ場面も残ります。
新しいモデルを片っ端から試したい・学習までやりたいならNVIDIA系。
静かに大きなモデルを動かしたいならMac。
そして「WindowsのままCUDAを持ち歩きたい」という願いに初めて応えるのがRTX Spark。
普段使いでMacとWindowsのどちらが向くかは、MacとWindowsのメリット・デメリット比較でも解説しています。
生成AIの「2台目」をどれにする? — 本命はMac M5 Max と RTX 5090(RTX Sparkは?)
生成AIの2台目選びが、今いちばん相談を受ける話です。
生成AIで仕事をしていると、手元の1台では足りなくなってきます。
学習用、推論用、画像生成用と、もう1台ほしくなる瞬間。
私も3台のデバイスを稼働しています。
1台では、到底たりない。
その2台目候補が、今こうなっています。
- もともとMacユーザーなら、メモリ・ストレージを盛った上位Macをもう1台
- いっそWindowsで、RTX 5090のようなハイエンドGPU機
- そこへ2026年6月、RTX Sparkが割り込んできた
迷う最大の理由は、3者が「得意なこと」も「弱点」もバラバラだからです。
スペックを正面から並べます。
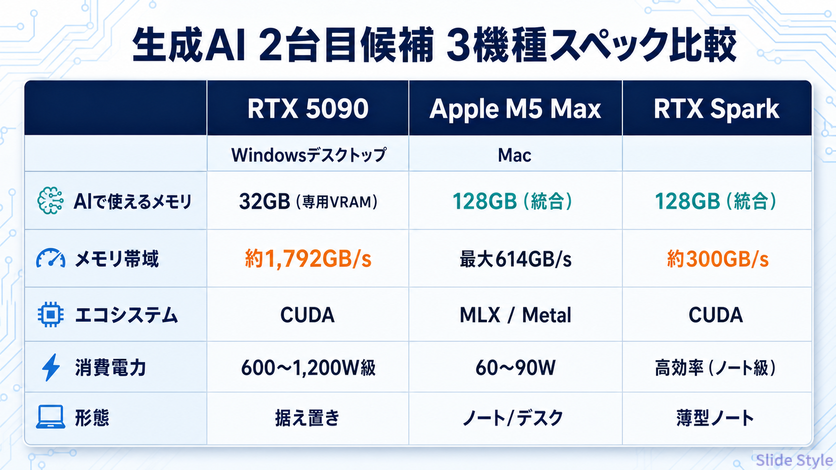
| 項目 | RTX 5090(Windowsデスクトップ) | Apple M5 Max(Mac) | RTX Spark |
| AIで使えるメモリ | 32GB(GDDR7・専用VRAM) | 最大128GB(統合) | 最大128GB(統合) |
| メモリ帯域 | 約1,792GB/s | 最大614GB/s | 約300GB/s |
| エコシステム | CUDA(業界標準) | MLX / Metal | CUDA |
| 消費電力(目安) | 600〜1,200W級 | 60〜90W | 高効率(ノート級) |
| 形態 | 据え置きデスクトップ | ノート/デスクトップ | 薄型ノート/小型デスク |
この表に、3者の性格がそのまま出ています。
RTX 5090は「速さと画像生成の王様、ただし容量の壁」。
帯域1,792GB/sは3者で断トツ。
小〜中サイズのモデル(〜32GB)なら一番速く、画像生成はCUDAのおかげでMacの数倍。
画像をひたすら回す人には、これが一番気持ちいい。
ただしVRAMが32GBで頭打ちなので、70B超の大きなモデルはそのままだと載りません。
電力もすごく、ファンも回る据え置き専用機。
Mac M5 Maxは「大きいモデルと静けさ、しかも帯域が速い」。
128GBの統合メモリで70B級も丸ごと載り、しかも帯域614GB/sはRTX Sparkより上。
消費電力は60〜90Wで、RTXの10〜20分の1。
実は、純粋な大規模モデルの推論速度では、Mac M5 MaxがRTX Sparkを上回る場面もあります。
弱点はCUDAではなくMLX系なので、CUDA前提の最新フレームワークは一手間かかること。
RTX Sparkは「128GB×CUDA×持ち運び、ただし帯域は控えめ」。
Macのような大容量統合メモリに、NVIDIAのCUDAを薄型ノートで両立。
これは今まで存在しなかった組み合わせです。
ただし帯域が約300GB/sと3者で一番低く、巨大モデルを動かすと速度は伸び切りません。
「CUDA資産を活かしたまま大きなモデルを持ち歩きたい」人のための1台、という立ち位置。
この3つは横並びの「三つ巴」に見えて、実は立っている土俵が違います。
まずRTX 5090は据え置きデスクトップ。
持ち運べるノートのMacやRTX Sparkとは、そもそも別カテゴリです。
「電源とスペースを用意して、最速と画像生成を取りにいく」と決めた人のための選択肢。
本当の比較は、RTX 5090を一度わきに置くと見えやすくなります。
残るのは、「1台で持ち歩きも据え置きもこなすノート」という同じ土俵に立つ2台、Mac M5 MaxとRTX Sparkです。
どちらも128GBの統合メモリを積める、数少ないノート。
ところが、この一騎打ちでRTX Sparkは苦しくなります。
帯域が約300GB/sと、Mac M5 Maxの614GB/sの半分以下。
開発で実際に回す7B〜70Bあたりのモデルは、この帯域がそのまま体感速度に効くので、同じモデルならMacのほうが速い。
RTX Sparkが勝てるのは、Macにも載りきらない超巨大モデル(120B級)を“とにかく載せる”一点だけ。
でもそこは生成50トークン/秒ほどで、対話しながら開発するには重すぎます。
だから私の見立てはこうです。
本気でローカルAI開発をするなら、本命はMac M5 MaxとRTX 5090の2台。
1台で携帯まで済ませたいならMac M5 Max、据え置きで最速と画像生成を取るならRTX 5090。
話題のRTX Sparkは、この2台の“いいとこ取り”に見えて、速度の壁で本命からは外れるというのが現時点の結論です。
投げかけた質問は早く回答してもらいたい。
そして、PDCAは早くまわしたい。
RTX Sparkが活きるのは、「CUDAを使いたい・巨大モデルを載せたい・持ち歩きたい・速度はある程度妥協できる」という条件がそろったとき。
その立ち位置を理解したうえでなら、面白い1台です。
そもそもGPUを選ぶときの基本の見方は、GPU選びの5つのポイントで書いています。
Claude Code を VS Code で動かすなら? — Windows on Arm・Windows・Mac の違い(2026年6月時点)

生成AIでコードを書く人が増え、「Claude CodeをVS Codeで使うなら、どのPCがいい?」という質問もよく受けます。
Claude Codeまわりは誤解が多いので、先に大事な前提を1つ。
Claude Codeの推論(AIが考える部分)は、手元のチップではなくクラウド側で走ります。
だから、トークン生成の速さ自体は、Mac・Windows・Windows on Armで基本的に同じ。
応答速度はネットワークとサーバー次第で、ローカルのCPUやGPUの性能では変わりません。
では何が変わるのか。
拡張機能の対応状況、ターミナルとの相性、そしてローカルの開発ツール(ビルドやテスト)の速さです。
2026年6月時点の実情を表にします。
| 項目 | Mac(Apple Silicon) | Windows(x86/x64) | Windows on Arm(RTX Spark等) |
| Claude Code本体 | ネイティブ動作 | WSL2推奨 | ネイティブ動作(ただし制約あり) |
| VS Code拡張のバージョン | 最新 | 最新(v2.1.9) | v2.0.46で更新停止中 |
| ターミナル/Unix親和性 | 最高(標準でUnix系) | WSL2で確保 | WSL2で確保 |
| 開発ツールチェーン | ネイティブで快適 | ネイティブ | Arm64ネイティブなら速い/x86はエミュレーション |
| AI応答(トークン速度) | 3者ほぼ同じ(クラウド処理) | 同左 | 同左 |
いちばん効くのが、Windows on Armの拡張機能の問題です。
Anthropicの公式GitHubに上がっている通り、Claude CodeのVS Code拡張は、Windows Arm64版が v2.0.46 で止まっていて最新版に更新できません。
x64マシンが最新の v2.1.9 を使えるのに対し、Arm64ユーザーは約2ヶ月分の更新を受け取れない状態です。
これはRTX Spark(Windows on Arm)でClaude Codeをメインに使いたい人には、現時点で無視できない弱点です。
かなりのデメリットではないでしょうか。
購入前に拡張機能のArm64対応が追いついたかを必ず確認したほうがよいです。
一方でMacは、今いちばん摩擦が少ない選択肢。
ターミナルが標準でUnix系、開発ツールもほぼネイティブ、拡張機能も最新が普通に動きます。
ファンレスで静かに1日中コードを書ける点も、地味に効きます。
Windows(x86/x64)は、WSL2(Windows上でLinux環境を動かす仕組み)を使うのが定番。
小さなオーバーヘッドは乗りますが、拡張機能は最新が使え、実用上は問題ありません。
拡張機能のArm64対応は、時間が解決する部分でもあります。
Anthropicが拡張のArm64対応を追いつかせ、Windows on Armのx86エミュレーション(ADK 2026世代で従来比+20%とされる改善)が進めば、差は縮まっていきます。
ただし「2026年6月の今」を切り取ると、Claude Code用途ではMacが一歩リード、というのが正直な評価です。
ローカルLLMを入れてClaude Codeで動かすなら? — RTX 5090・Mac M5・RTX Spark で何が変わる
さっきと前提を入れ替えます。
クラウドではなく、自分のPCにローカルLLMを入れて、Claude Codeをそれに繋ぐケース。
この瞬間、チップの性能がすべてを決めます。
モデルを動かすのが、クラウドではなく手元のPCになるからです。
先に、押さえておきたい言葉を5つだけ
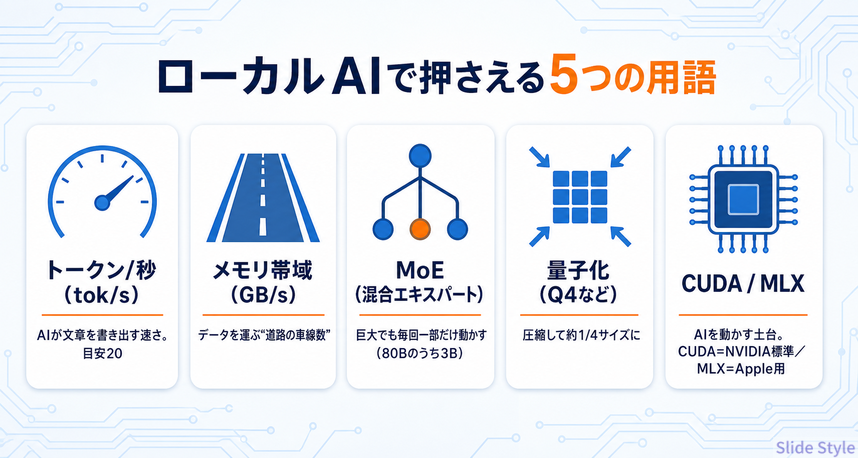
数字の前に、専門用語を最小限だけ噛み砕いておきます。
この5語さえ押さえれば、後の表はぜんぶ読めます。
- トークン/秒(tok/s):AIが文章を書き出す速さ。人が快適に読む目安は20前後で、超えれば待ち感はほぼ消え、10を切ると“少し待つ”体感になります
- メモリ帯域(GB/s):メモリからチップへデータを送る“道路の車線数”。広いほど一度に多く運べて、ローカルAIの速度はほぼこの帯域で決まります
- MoE(混合エキスパート):巨大でも毎回その一部だけを動かす方式。Qwen3-Coder-Next 80Bは、80Bのうち毎回3Bぶんだけ使って速度を稼ぎます
- 量子化(Q4など):モデルを圧縮してメモリ使用量を減らす手法。Q4なら元の約4分の1サイズになり、精度を少し割り引く代わりに手元で動きます
- CUDA / MLX:AIを動かす土台(部品をつなぐ共通言語)。CUDAはNVIDIA製GPUの業界標準、MLXはApple製チップ用で、最新ツールの多くはCUDA前提で作られます
まず「できるのか?」から。
2026年は、もう難しくありません。
Ollamaがv0.14.0(2026年1月)からAnthropicのMessages APIにネイティブ対応したので、Claude Codeを翻訳レイヤーなしで直接ローカルモデルに繋げます。
LiteLLMのようなプロキシを挟む方法もあり、設定は環境にもよりますが数十分ほどで済みます。
ただし、ひとつ釘を刺しておきたいことがあります。
ローカルLLMは、どれを選んでもクラウドのClaude本体よりコーディング能力が落ちます。
複雑な多段タスクでの精度が下がり、ツール呼び出しが不安定になり、存在しないファイルパスを書くことも増える。
ローカル化は「速さや賢さ」ではなく、プライバシー・コスト・オフラインのための選択だと割り切るのが正解です。
その上で、ローカルで使えるコーディングモデルの実情です。
エージェント用途で評価が高いのは、Qwen3-Coder-Next(80BのMoEモデル・Q4で約35〜40GB)やKimi K2.6など。
これらの大型モデルは、メモリに丸ごと載せるなら128GBクラスが要ります。
一方、24〜32B級(Devstral 24B・Qwen 27B等)なら、24〜32GBのVRAMでも動きます。
では、3プラットフォームの相性です。
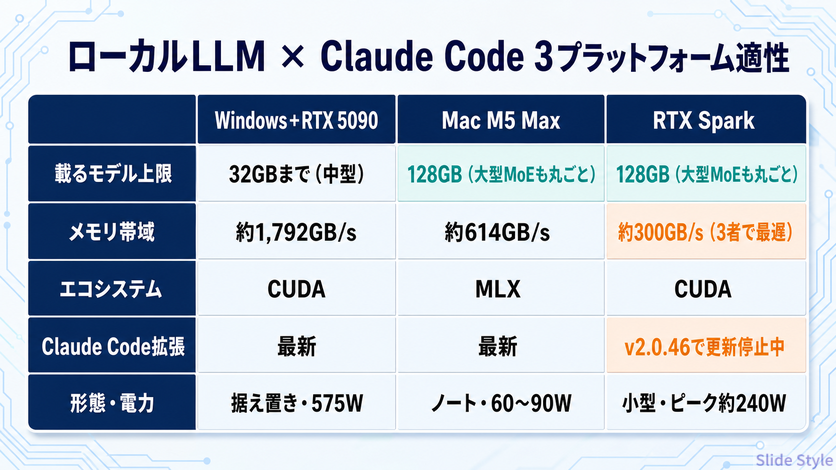
| 観点 | Windows+RTX 5090 | Mac M5 Max | RTX Spark |
| 載るモデルの上限 | 32GBまで(中型が上限) | 128GB(大型MoEも丸ごと) | 128GB(大型MoEも丸ごと) |
| メモリ帯域 | 約1,792GB/s(GDDR7) | 約614GB/s(統合) | 約300GB/s(LPDDR5X・3者で最遅) |
| エコシステム | CUDA | MLX | CUDA |
| Claude Code本体 | WSL2推奨・拡張は最新 | ネイティブ・拡張は最新 | 拡張がv2.0.46で更新停止中 |
| 形態・消費電力 | 据え置き・カードTDP 575W | ノート/デスク・60〜90W | 小型・システムピーク約240W |
Windows+RTX 5090は「中型モデルを最速で回す」型。
帯域1,792GB/sで、24〜32B級のコーダーモデルなら一番速く返してきます。
CUDAなので新しいモデルの対応も早い。
弱点はVRAM 32GBの壁で、80B級のMoEは全部載せきれず、システムメモリに溢れた分だけ失速します。
Mac M5 Maxは「大型エージェントモデルを現実的な速度で」型。
128GBの統合メモリで、Qwen3-Coder-NextのようなMoEも丸ごと載ります。
帯域614GB/sはRTX Sparkの倍近くあり、大型モデルの推論速度でSparkを上回ります。
しかもClaude Code本体がMacではネイティブで、拡張も最新が動く。
私が今これを書いている時点で、ローカルLLM×Claude Codeの総合バランスは、このMacが一番素直です。
RTX Sparkは「理想形、ただし今はまだ待ち」型。
128GBの大容量とCUDAを薄型ノートで両立する、という発想自体は3者で唯一無二。
ただ帯域が約300GB/sと最も低く、大型モデルを動かすとトークン速度が伸び切りません。
加えてWindows on Arm版のClaude Code拡張が更新停止中で、発売も2026年秋。
ポテンシャルは高いのに、2026年6月の今は実力をフルに出せない、というのが実際のところです。
実測トークン速度 — 「帯域がすべて」が数字で見える
前の章まではスペック上の性格の話でした。
ここからは、公開されている第三者の実測ベンチマークの数字で裏を取ります(NVIDIA・Apple公式の出荷スペックではなく、同一テスト環境での計測値)。
まず、RTX Spark と同じGB10シリコンを積む開発機(DGX Spark)と、RTX 5090 を 同じ人が同じモデル(gpt-oss 20B)で測った 値がいちばん公平です。
| gpt-oss 20B(同一テスト) | RTX 5090 | RTX Spark(GB10) |
| トークン生成 | 約325トークン/秒 | 約85トークン/秒 |
| 入力(プロンプト)処理 | 約12,809トークン/秒 | 約3,685トークン/秒 |
生成で約3.8倍、入力処理で約3.5倍の差。
体感で言うと、85トークン/秒でも読むには十分速い一方、長いコードを一気に書かせると325との差が待ち時間としてはっきり出ます。
同じ20Bモデルでこれだけ開くのは、演算力ではなくメモリ帯域の差がそのまま出ているからです。
RTX 5090 の1,792GB/sに対し、Spark系は約300GB/s。
さっきの“道路の車線数”でいえば、5090は片側6車線、Spark系は1車線という開き。
ローカル推論のトークン速度は、ざっくり「メモリ帯域 ÷ モデルのサイズ」で決まるので、帯域が約6分の1なら速度もその比率に引っ張られます。
では大型モデルならどうか。
GB10で gpt-oss 120B を動かすと、生成は約50トークン/秒・入力処理は約1,821トークン/秒まで落ちます。
同じ128GB級のMac M5 Max(帯域614GB/s)は、70BクラスのQ4で約28トークン/秒、122BのMoEで約15トークン/秒という実測値。
(実測値の出典)これらの数値は私の計測ではなく、公開されている第三者ベンチマークの引用です。
DGX Spark(GB10)とRTX 5090の gpt-oss 計測は Robert McDermott氏のレビュー、Mac M5 Maxの計測は LLM Check のベンチマーク を参照しています。
いずれもメーカー公式の出荷スペックではなく、第三者が同種の条件で測った参考値です。
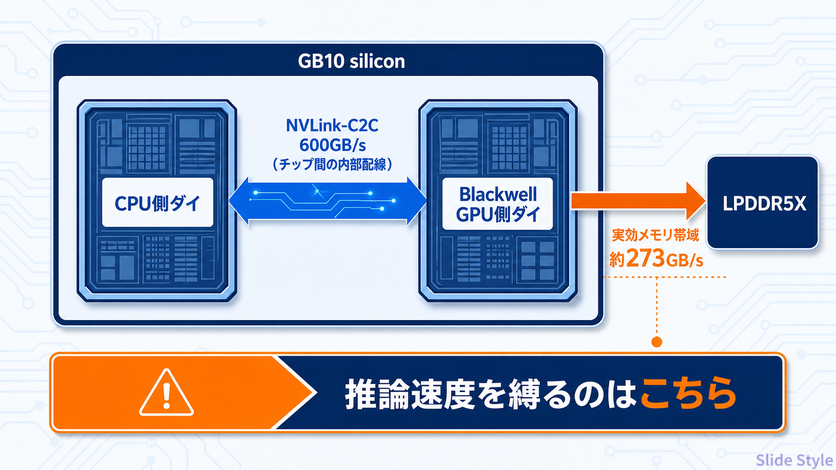
「600GB/s」の罠 — NVLink-C2Cはメモリ帯域ではない
もう1つ、混同しやすい数字を切り分けておきます。
GB10の資料には NVLink-C2C 600GB/s という値が出てきますが、これはメモリ帯域ではありません。
GB10はCPU側ダイ(メモリ管理を含む)とBlackwell GPU側ダイの2チップ構成で、その チップ間をつなぐ内部配線 が600GB/sです。
一方、GPUが実際に外部のLPDDR5Xメモリを読み書きする帯域は約273GB/s。
推論速度を縛るのは後者のメモリ帯域なので、「600GB/sあるなら速い」と読むと判断を誤ります。
公式スペックの数字を、正しい場所に当てはめる必要があります。
電力と総コスト — 速いだけでは決まらない
最後に、見落とされがちな電力です。
RTX 5090はカード単体でTDP 575W、瞬間ピークは700Wを超えます。
これは画像生成や学習を回すなら頼もしい一方、電気代と発熱・騒音という形で毎日跳ね返ってきます。
対してGB10機はシステム全体のピークで約240W、アイドルは約25W前後。
Mac M5 Maxは負荷時でも60〜90Wに収まります。
仮に1日8時間ローカル推論を回すなら、フル稼働時の消費電力はRTX 5090がSpark系の2倍以上、Macの6〜9倍にあたる計算です。
本体価格だけでなく、数年使ったときの電気代まで含めて見ると、省電力2台(Mac・Spark系)と高性能・高消費電力のRTX 5090で、性格がはっきり分かれます。
私が3年前に「LLMをローカルで構築する場合の環境を調べた時も、最後は電力問題を解決できない」という結果に。
モデルの賢さは、どれを選んでも“クラウドのClaude未満”
速度の次は中身です。
ローカルで評価の高いコーダーモデル Qwen3-Coder-Next(80B MoE・3Bアクティブ)は、SWE-bench Verifiedで約67%。
これはクラウドのClaude Sonnet 4.6(79.6%)やOpus 4.7(87.6%)に明確に届かない水準です。
数字の差はそのまま、複雑なタスクでのツール呼び出しの安定性や多段作業の精度差として出ます。
どのプラットフォームでローカル化しても、賢さの天井はクラウドのClaude本体より低い、という前提は変わりません。
だからこそ、ローカルのLLMを強化するのが重要になる。
LLMの講座もそこが最終地点になっている。
3者の強み・弱点 — 数字でまとめると
| プラットフォーム | 強み(数字の裏付け) | 弱点(数字の裏付け) |
| RTX 5090 | gpt-oss 20Bで生成325トークン/秒・入力12,809トークン/秒/帯域1,792GB/s | VRAM 32GBの壁/カードTDP 575W・瞬間ピーク700W超 |
| Mac M5 Max | 70B Q4で約28トークン/秒・122B MoEで約15トークン/秒/帯域614GB/s・消費60〜90W | MLX(CUDA非対応)で最新CUDAツールは対応待ち |
| RTX Spark(GB10) | 128GB×CUDA×携帯を1台で両立/システムピーク約240W・アイドル約25W | gpt-oss 20Bで生成85トークン/秒(5090の約1/3.8)/帯域273GB/sで3者最遅 |
この表が、3者の性格を数字でそのまま表しています。
速さのRTX 5090、容量と省電力のMac、理想形に見えて帯域が遅いRTX Spark。
本気でローカルLLM×Claude Codeをやるなら、本命はMac M5 MaxとRTX 5090の2台。話題のRTX Sparkは、帯域273GB/sの遅さで日常的に回す開発機としては本命から一歩外れ、活きるのは巨大モデルをCUDAで持ち歩きたいという限定用途です。
ただし、これは2026年6月時点の話。AI関連は毎日、いや毎時間アップデートが溢れ、状況は一変します。
結局、3台のどれを選ぶか — タイプ別の判断

3台の実測を踏まえ、ローカルAI前提で割り振ります。
- 1台で携帯も据え置きも済ませたい → Mac M5 Max。大型モデルが丸ごと載り、帯域614GB/sで速度も現実的、Claude Code本体もネイティブ。今すぐ買えるのも強い
- 最速と画像生成を取りに行く・据え置きでよい → RTX 5090。中型モデルなら3台で一番速く、画像生成はCUDAで圧倒。VRAM 32GBの壁と電力は割り切る前提
- CUDAで巨大モデルを“持ち歩きたい”という限定用途のみ → RTX Spark。帯域300GB/sの遅さを許容できて、Macに載らない120B級をノートで運びたい人向け。発売は2026年秋、実機の速度とArm対応待ち
本音を言えば、私が本気でローカルAIをやるなら、いま動けるMac M5 Maxを軸に、最速がほしい場面で据え置きのRTX 5090を足す形を選びます。
RTX Sparkは、発売後に実測の速度とArm対応を見て、限定用途にハマるならという距離感です。
よくある質問(FAQ)

ローカルでLLMを動かすには、どれくらいのメモリが必要ですか?
24〜32B級のコーダーモデル(Devstral 24B・Qwen 27Bなど)なら、24〜32GBのVRAMでも動きます。
Qwen3-Coder-Next(80B MoE)のような大型を丸ごと載せるなら、128GBクラスの統合メモリ(Mac M5 MaxやRTX Spark)が目安です。
ローカルLLMは、クラウドのClaudeと同じくらい賢いですか?
いいえ。ローカルで評価の高いQwen3-Coder-Next(80B)でもSWE-bench約67%で、クラウドのClaude Sonnet 4.6(79.6%)やOpus 4.7(87.6%)には届きません。
ローカル化はプライバシー・コスト・オフラインのための選択で、賢さの天井はクラウドのClaude本体より低い前提になります。
SnapdragonはNVIDIAが作っているのですか?
いいえ、SnapdragonはQualcomm製です。
RTX SparkはNVIDIA製で、CPU設計はMediaTekが担当した別物。
両者はWindows on Armの競合関係です。
RTX Sparkでも、Snapdragonと同じく一部アプリが遅くなりますか?
Arm64ネイティブ非対応のアプリはエミュレーション動作になり、性能が落ちます。
これはWindows on Arm共通の事情で、2026年秋時点ではAdobe主要アプリなどネイティブ化が進み、状況は改善しています。
生成AIをやるならMacとWindowsどちらが良いですか?
速度と対応フレームワークの広さならCUDAのNVIDIA系、大容量モデルと省電力ならMacが有利です。
RTX Sparkは両者の利点を1台に狙った設計ですが、帯域が低く速度の面では本命のMac M5 MaxやRTX 5090に一歩譲ります。
RTX SparkとApple M5 Max、メモリ性能はどちらが上ですか?
両方とも最大128GBの統合メモリですが、帯域はM5 Maxが614GB/s、RTX Sparkが300GB/s。
帯域ではM5 Maxが上回り、RTX SparkはCUDAエコシステムで差別化します。
128GBの統合メモリは何の役に立つのですか?
CPUとGPUがメモリを共有するため、コピーの手間なく巨大なAIモデルをまるごと載せられます。
1,200億パラメータ(120B)級のLLMを100万トークンのコンテキストでローカル実行できる点が、開発者にとって最大の利点です。
Claude CodeをVS Codeで使うなら、RTX SparkとMacどちらが良いですか?
AIの応答速度はクラウド処理なので3プラットフォームでほぼ同じです。
ただし2026年6月時点では、Windows on Arm版のVS Code拡張がv2.0.46で更新停止中のため、Claude Codeをメインに使うならMac(Apple Silicon)が一歩リードします。
まとめ
生成AIをローカルで動かすなら、本命はMac M5 MaxとRTX 5090のどちらかがこの記事の結論です。
1台で携帯まで済ませたいならMac M5 Max。大型モデルが丸ごと載り、帯域614GB/sで速度も現実的、Claude Code本体もネイティブに動きます。
据え置きで最速と画像生成を取るならRTX 5090。中型モデルなら3台で一番速く、VRAM 32GBの壁と電力だけ割り切る前提です。
話題のRTX Sparkは「128GB×CUDA×持ち運び」という、ほかにない組み合わせを持ちながら、帯域300GB/sの遅さで、日常的に回す開発機としては本命から一歩外れます。
活きるのは、Macにも載らない巨大モデルをCUDAで持ち歩きたい、という限定用途。
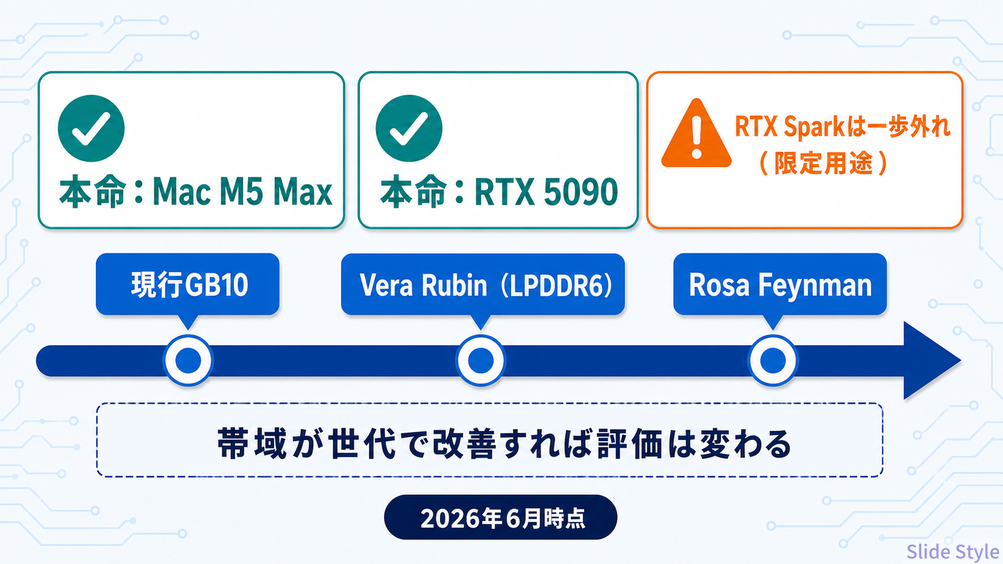
ただ、NVIDIAはこの第1世代で止めるつもりはなく、次世代はLPDDR6を積む「Vera Rubin」世代、その先に「Rosa Feynman」世代を予告しています。
いまの弱点である帯域が世代を追って埋まっていけば、RTX Sparkの評価は変わってきます。
本命から外れるのはあくまで2026年の今の話で、AI関連の環境はすぐにアップデートされます。
判断の鍵は、価格でも話題性でもなく、どのサイズのモデルを・どれくらいの速度で回したいか。
発売は2026年秋。実測の速度とArm対応の環境の進化を見たうえで、判断したいモデルといってもよいです。
参考ソース(公式)
- NVIDIA公式 製品ページ:https://www.nvidia.com/ja-jp/products/rtx-spark/
- NVIDIA Newsroom(RTX Spark / Microsoft 共同発表):https://nvidianews.nvidia.com/news/nvidia-microsoft-windows-pcs-agents-rtx-spark
- Arm 公式 newsroom:https://newsroom.arm.com/news/arm-agentic-pc-era-with-nvidia-rtx-spark
- MediaTek 公式プレスルーム:https://www.mediatek.com/press-room/mediatek-collaborates-with-nvidia-on-rtx-spark-to-power-the-next-wave-of-windows-pc-experiences
- Microsoft Windows Experience Blog:https://blogs.windows.com/windowsexperience/2026/05/31/introducing-a-powerful-new-chapter-for-windows-pcs-accelerated-by-nvidia-rtx-spark/
- Apple Newsroom(M5 Pro / M5 Max・2026年3月):https://www.apple.com/newsroom/2026/03/apple-debuts-m5-pro-and-m5-max-to-supercharge-the-most-demanding-pro-workflows/
- Adobe 公式(Windows on Arm 対応状況):https://helpx.adobe.com/x-productkb/multi/windows-arm-support.html
- Claude Code 公式ドキュメント(VS Code):https://code.claude.com/docs/en/vs-code
- Anthropic 公式GitHub(VS Code拡張 Windows Arm64 更新停止 Issue):https://github.com/anthropics/claude-code/issues/18515
- Microsoft Learn(Windows on Arm / x86エミュレーション):https://learn.microsoft.com/en-us/windows/arm/apps-on-arm-x86-emulation
- Ollama 公式ドキュメント(Claude Code 連携):https://docs.ollama.com/integrations/claude-code